こんにちは!組込みソフトウェアエンジニアの村田です。今年入社したばかりなのでまだ「これやってます!」みたいなことは言えないのですが、それでも強く生きています。さてTech Blogということで技術情報について何にしようか悩んでたのですが、最近の流行りに乗って機械学習を簡単にやってみるというテーマにしました。キーワードは「枯山水」と「TensorFlow」です。
枯山水とTensorFlowの関係
まずはキーワードである「枯山水」と「TensorFlow」について紹介しましょう。
「枯山水」とは”水のない庭のことで、池や遣水などの水を用いずに石や砂などにより山水の風景を表現する庭園様式”(Wikipediaより)のことです。ヘッダーの画像は「京都フリー写真素材」の素材を使わせてもらっています。そして、この枯山水を自分で作るボードゲームがあるのです。ルールは簡単!「砂タイル」と「石」をおいて図1右側にあるような美しい庭を作ります。タイル同士のつながりや石の配置によって得点を計算するのですがこれが手順が多くてめんどくさい。以下に点数計算の手順を列挙します。
- 砂の基礎点
- 苔の基礎点
- 対称性ボーナス
- 渦ボーナス
- 砂紋の評価
- 石の基礎点
- 石組みの評価
- 名庭園
- 徳
めんどくさくなったら自動化するのがプログラマですよね。というわけで、図1の右側にあるよう な庭園画像を画像処理して点数を計算します。ここで登場するのが「TensorFlow」なわけです。これはGoogleが開発している機械学習用のライブラリで、誰でも使うことができます。機械学習とは機械が学習をしてそれをもとになにかをするというものですが、最近では囲碁とか将棋のAIで使われていることがニュースでやっていたりしますよね。あれです。TensorFlowについて詳しく知りたい方はここをご覧ください。
な庭園画像を画像処理して点数を計算します。ここで登場するのが「TensorFlow」なわけです。これはGoogleが開発している機械学習用のライブラリで、誰でも使うことができます。機械学習とは機械が学習をしてそれをもとになにかをするというものですが、最近では囲碁とか将棋のAIで使われていることがニュースでやっていたりしますよね。あれです。TensorFlowについて詳しく知りたい方はここをご覧ください。
Let’s TensorFlow!
学習モデル
では、さっそくTensorFlowをつかって機械学習していきましょう。TensorFlowを使うにはどういった画像を入力して何を出力してもらうかを決めなければいけません。枯山水の得点計算の方法には以下の2つの手法が考えられます。
<手法1> 入力:庭園画像→出力:点数
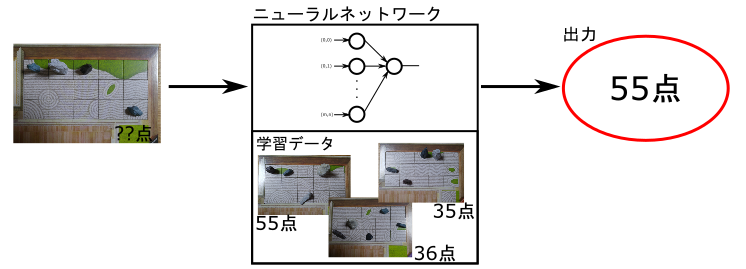
図2を御覧ください。左の??点となっている画像がこれから得点計算をさせたい画像になります。真ん中は入力と似たような画像にラベルと呼ばれるものをセットにしてニューラルネットワークに学習させています。学習データをもとにこの画像が何点っぽいのかという出力が出てきます。
この手法では画像の前処理も後処理も必要なく、ニューラルネットワークの処理のみで構成できるのがいいところです。この場合、学習には完成形の庭の写真とそれに対応する点数をラベルとして用います。入力には画像全体を使うことになるので画素数の設定によっては処理が非常に遅くなってしまうという問題がある一方、枯山水においては取りうる点数が0~100点(実際に取ることになる点数の範囲はもっと狭い)だけなので出力が最大で101個だけで済みます。
この学習方法には一つ問題があります。学習データの用意が非常に手間なのです。この学習に一つの点数あたり100枚ぐらいとりあえず用意すると1万枚のデータが必要になります。枯山水で遊び、ゲームが終わるたびに写真を取って点数ラベルを付ける作業によって4枚の学習セットが得られ、1ゲームあたりにかかる時間は約1時間で、それぞれのゲームで最大4枚の庭が完成します。データ数が10000個なので、2500ゲーム。つまり2500時間。ぶっ通しでやると不眠不休で約104日間枯山水をやらなければいけないのです。
<手法2>入力:タイル画像→出力:タイルの種類
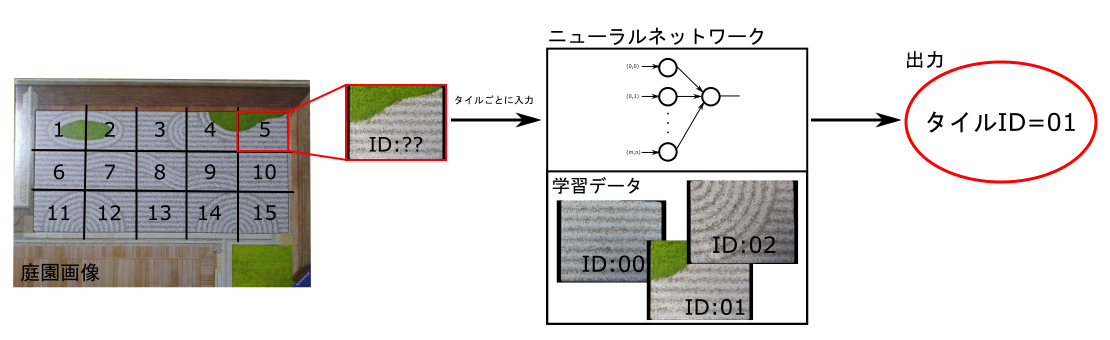
図3は手法2のデータの流れになります。今度はニューラルネットワークには点数を出すのではなく、タイルの順序をだしてもらおうという手法です。まず、庭園画像を左上から右下へむかって番号をつけ、それぞれのタイルの画像を切り出します。この切り出した画像をおなじようにタイルのみの画像で学習したニューラルネットワークに突っ込んで庭園の何番目のタイルはIDいくつですという結果を出力してもらいます。そしてこの結果をもとに得点計算のプログラムを走らせて結果を得られるのです。
この構成ではまず先程書いたとおり、タイルの識別部分以外をニューラルネットワークとは別に作るということが手法1との違いになります。タイル1枚あたりの画素数は庭園全体に比べて小さくて済むので入力が小さくなり学習が早くできるという利点があります。
学習データはどれくらい集められるのでしょうか。まずはタイルが22種類あります。さらに石が25種類、向きが2種類で合計で1100種類のラベルが存在することになります。1種類の画像を100枚収集するのに10分かかるとすると11000分(約18時間)でデータが集められます。すごく早い!
どちらのモデルがニューラルネットワークとして適切かというと一番目のほうがニューラルネットワークだけで完結するので適切だと僕は思います。しかし、個人の範囲では少々時間がかかりすぎてしまうので今回は二番目の手法でやってみたいと思います。
学習データの集め方
学習データはひたすらタイルの写真を撮り続けました。データを加工しやすいように背景に単色の画用紙を用いるといいです。この次に何をやればいいのかわからない人は「opencv hsv 抽出」と検索してみるとすべてがわかります。
プログラム
ではいよいよTensorFlowです。TensorFlowの公式ホームページにはチュートリアルがあり初心者でもわかるように(わかるとは言っていない)サンプルプログラムといっしょに説明がされています。機械学習ではMNISTとよばれる手書きの0~9の数値が書かれた画像を識別する、プログラムで言うHello World的なものがあります。TensorFlowでもこれのサンプルプログラムをもとに使い方をわかりやすく(わかるとは言っていない)説明してくれているのです。このプログラムをMNIST以外の画像でも使えるようにしました。
https://bitbucket.org/muratatetsuya/kantan_tensorflow
参考にしたサイト
評価
最後に重要なのが作ったプログラムの評価です。表に結果をまとめました。
| 画像サイズ[px] | 学習時正答率[%] | 庭園画像正答数[枚] | 学習時間[s] |
| 60 x 70 | 97.6 | 7 | 9.32 |
| 120 x 140 | 97.3 | 9 | 22.6 |
| 240 x 280 | 98.4 | 10 | 90.5 |
| 480 x 560 | 98.4 | 6 | 338 |
まず学習時正答率とは学習データと同じ手法で作られた画像で学習時に使われていない画像で学習した後のニューラルネットワークによりどのタイルであるかを推定した結果になります。画像サイズに関係なく100%に近い正答率が出ています。一方庭園画像正答率というのは完成した庭園画像から15枚のタイル画像を切り出しリサイズしたものを推定したときの正答数になります。いずれも正答率が7割に満たない結果となりました。画像サイズが大きければ大きいほど判断材料が上がり精度が良くなるのかと考えていたのですが、このデータをみるとちょうどいい画像サイズがどこかにあるような感じがします。
では、学習時と使用時で正答率が変化してしまったのはなぜでしょう。一つの原因としては学習用のデータと庭園の画像から切り出されたタイル画像が違うことが考えられます。図3は今回間違いが多かった2つの画像の学習時と庭園の画像を並べたものになります。2つの画像の大きさは一緒なのですが、明るさが違います。これくらいの違いは見分けてもらえないと自動化ができないのですが、このくらいの違いを見分けられるようになるためには学習時の画像にさまざまな状況でのデータが必要となりそうです。

今回はTensorFlowを使ったニューラルネットワークのとても簡単なモデルを用いて評価したのでこのような悲惨な結果となってしまいましたが、画像を前処理したり、ニューラルネットワークの構成を変えたりすることでまた違った結果が得られると思います。快適徳ライフへの道はまだまだ長そうです……とりあえず、流行りである機械学習をやったことがあるという事実が大事なのでここらへんにしておきましょう。
最後になりますが、枯山水はとてもおもしろいボードゲームですし、徳が積めるので日頃、徳が足りないなーという方はぜひやってみてください。
それではー。
[blogcard url=”https://www.amazon.co.jp/%E3%83%8B%E3%83%A5%E3%83%BC%E3%82%B2%E3%83%BC%E3%83%A0%E3%82%BA%E3%82%AA%E3%83%BC%E3%83%80%E3%83%BC-%E6%9E%AF%E5%B1%B1%E6%B0%B4-%E6%96%B0%E8%A3%85%E7%89%88/dp/B00RCHUQG2″]